Introduction
In our previous blog, we compared Delta 1.2.0, Iceberg 0.13.1 and Hudi 011.1 and we published our findings only to find out that Onehouse saw a misrepresentation of the true power of Apache Hudi.
Although we disagree, we took this seriously and we decided to run the benchmark again using their configurations. We share in this blog our vision on how benchmarks should be made, we also take a deep dive into Hudi’s tuning and discuss its influence on the overall performance.
Benchmark Results
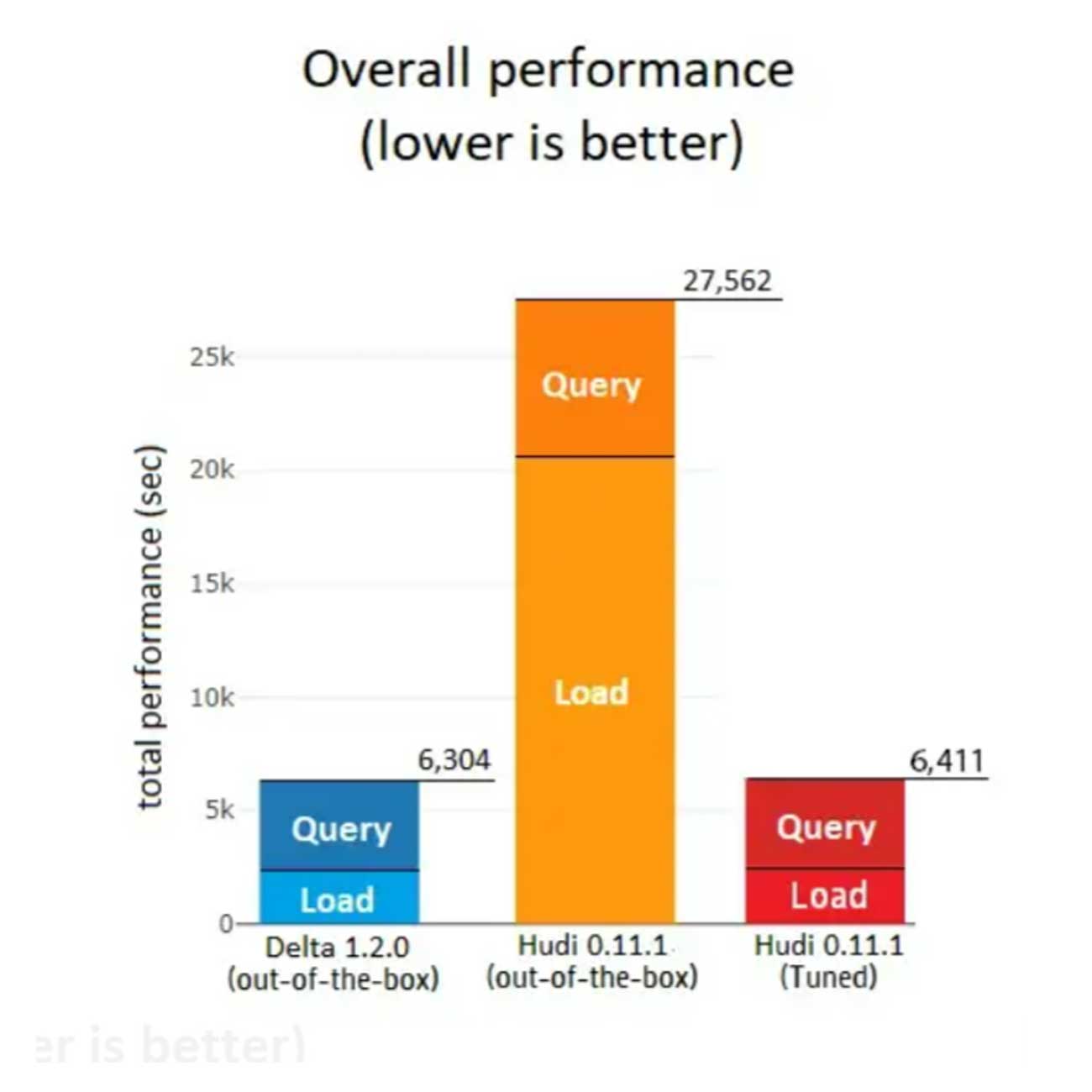
1. Overall performance
After tuning Hudi’s configs, Delta remained the fastest overall, with a slight, negligible difference.
Tuned Hudi’s overall performance improved and was 4.29X faster than the out-of-the-box Hudi.

2. Load performance
Delta remained the fastest in load performance too, and also, with a negligible difference.
Tuned Hudi’s load performance was 9.35X faster than the out-of-the-box Hudi.[chart-2]

3. query performance
After tuning, Hudi was 1.38X faster than the out-of-the-box Hudi. Thus, it reached a similar performance to the out-of-the-box Delta.[chart-3]

Hudi’s tuning analysis
To improve the Hudi performance, Onehouse recommended tuning some Table, Spark DataSource, Storage and Metadata configurations. This a lot of tuning to do especially if we know that Hudi has in total more than 70 spark datasource config, 60 write config, more than 15 storage config and more than 20 Metadata config with dozens of other configurations. This is exactly the kind of complexity that we wanted to avoid by running the benchmark without any tuning for all 3 formats and only using their default configurations. Otherwise there will always be things to tune and tweak for every format, everyone will look good in his benchmarks and users will be dragged into a lot of complexity with little or even negative impact on their day-to-day workloads.
It is also important to state that Hudi’s tuning was too technical and required deep understanding of how it functions under the hood. Some of the tuning choices don’t make sense for regular users as it “appears” to contradict the documentation, other choices can only be backed up by experts and others are simply made to mimic Delta’s configs.
Here are few of the perplexing config choices as well as some that we simply don’t agree on making:
1. Disable Metadata tables for Hudi.

Metadata tables are enabled by default on Hudi 0.11.1 and according to the Hudi documentation, they significantly improve read/write performance. So disabling this configuration to make Hudi’s performance better appears to be at odds with the tuning intent. We need to have the Onehouse Hudi exterptise to make such a counter intuitive decision. Also this kind of custom and sophisticated tuning can have a very bad impact on the benchmark integrity. It opens the door to questions like why not try similar things on Delta and Iceberg (disable statistics collection for example).
Actually, the 2X performance improvement made by Iceberg 0.13.1 compared to its 0.13.0 version was without any tuning efforts (see previous blog). It was Iceberg’s out-of-the-box performance. For Delta 1.2.0 there was a 15% load performance degradation compared to its 1.0.0 version. Any tuning efforts to improve it should not be part of the benchmark. In fact, we routinely tune Iceberg, Hudi and Delta and run benchmarks on them but we chose not to share the results because we believe that the out-of-the-box performance is what matters most for the clients.
2. Onehouse tuned Hudi’s file-size to match Delta’s setting.

Why does hudi need to match Delta’s default settings? We think that this kind of tuning affects the integrity of the benchmark too. To properly run a benchmark, we should not run SUT (system under test) A using its default settings and then use some of them to tune SUT B. Every SUT needs to be tested using its own default configuration and without making any observations on the others. If the default Delta file size is more optimal than Hudi’s file size even for Hudi, why not make it the default for Hudi too?
3. Changing the compression codec for Hudi to snappy.
While Hudi uses gzip as the default compression codec, Delta uses Snappy. So again even if we decide to tune one SUT (which we think is not the right way of running benchmarks), tuning decisions should not be inspired by what the other SUT configuration is, otherwise this will be just tuning for the sake of benchmarking. If Snappy is better for Hudi, this should be reflected in the Hudi default configurations.
4. fallback to the parquet write legacy format.

According to the Hudi documentation, if this is enabled, data will be written in the way of Spark 1.4 and earlier. This isn’t a straightforward tuning action to make. Indeed, using the spark 1.4 way of writing data when using spark 3.2 doesn’t make a lot of sense at least for simple Hudi users (like us). It requires experts on the matter.
Conclusion
One of the promises of a Lakehouse is to provide the simplicity and performance of a Datawarhouse. Users on a Lakehouse should focus on their business use cases instead of fighting configurations to pick the right file size, choose the best compression or run maintenance operations. The workloads on a Lakehouse need to just run as expected for big and small tables, high or low concurrency queries and for all types of workloads. This is why we strongly think that benchmarking open formats needs to be done without any tuning efforts and the out-of-the-box performance is what needs to be measured. We know that each of the open formats has its own room for improvement, but this should be the direction if we want the Lakehouse to be successful.
If you have any questions, feel free to contact us at databeans-blogs@databeans.fr


